데이터 라이프 사이클(Data Life Cycle) 에 대해 다루고 있습니다. GMP 데이터가 생성되고 나면, 그 다음 단계인 "데이터 가공(Data processing) 단계로 넘어가게 됩니다. 가장 DI Risk 가 많은 단계에 진입하게 되는데, Data processing 단계에서 유의해야할 DI 이슈는 무엇이 있을지 아래 내용을 확인하시기 바랍니다.

[목차]
◾ 데이터 프로세싱(Data processing) 의 설명
◾ 데이터 프로세싱 단계에서 정의하고 평가되어야 할 DI Risk(위험)
데이터 프로세싱(Data processing) 의 설명
GMP 활동으로 얻은 최초의 데이터 (전자데이터 or 종이 출력 데이터/기록) 는 그대로 보고(Report) 되는 경우도 있으나, 초기 전자데이터 (Raw data 라고 보통 부르는) 들은 검증된 S/W 의 기능을 통해 최종 보고를 위한 형태로 가공(Processing) 하거나, 정량/정성 평가를 위한 기준 값에 맞춘 가공 절차가 진행되어야 합니다.
예)
함량 분석을 위한 HPLC 분석을 통해 최초 얻어진 Raw data(= Chromatogram) 은 그 자체만으로는 보고할 수 없는 형태의 데이터입니다. (Peak ID 나, Peak 면적값의 계산 불가) 따라서, 해당 Chromatogram 은 SOP 에 정해진(검증된) Method 를 통해 사전에 정의한 processing parameter 를 통해 보고 가능한 결과로 가공됩니다.
이때 중요한 것은 데이터의 가공 과정에서 수행한 Action (적분, 변경, peak ID 부여 등) 의 이력은 모두 Audit trail 등을 통해 확인할 수 있어야 합니다. 해당 데이터 (Raw data + Processed data + action log) 는 해당 데이터의 최종 보고를 위한 Reivew 과정에서 Reviewer 에 의해 모두 직접 확인되어야 합니다.
Re-processing (재 가공) 의 경우, 데이터 완전성(DI) 측면에서는 민감한 절차입니다. 어떤 시스템의 경우는 최초 Processing 이후 Re-processing 을 임의로 하지 못하도록 제한이 가능하나, 대부분의 시스템은 최초 processing 이후 언제든지 Re-processing 되는 위험이 있습니다.
따라서, Re-processing 에 대한 DI 위험 레벨을 감안해 Re-processing 의 수행 가능 상황 및 수행을 위한 표준 Procedure 가 반드시 수립되어야 합니다.
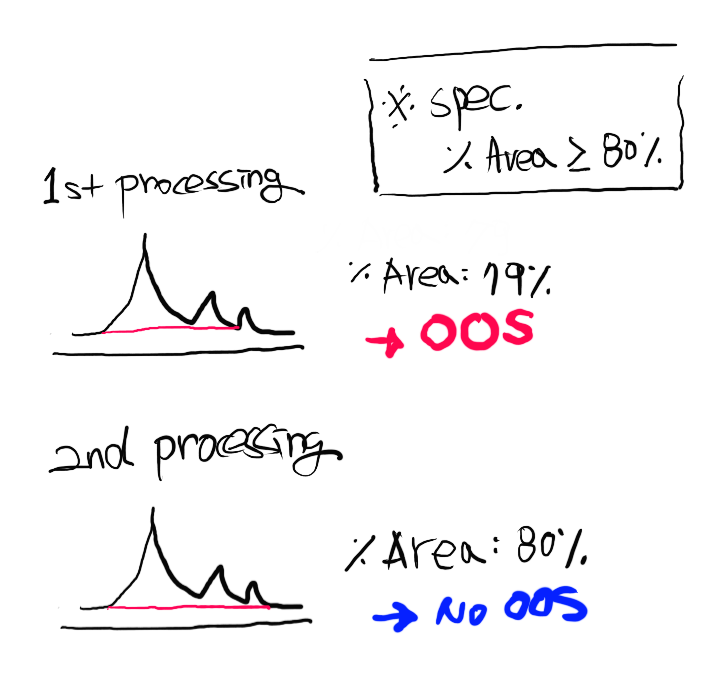
▲ 1st processing 결과가 79% 로 OOS 결과를 얻었을 때, 2nd processing 을 시도해 80% 결과로 Reporting 했다면, 이때의 Reprocessing 은 철저히 정당성(Written procedure 에 근거한) 이 명시되어야 합니다.
데이터 프로세싱 단계에서 정의하고 평가되어야 할 DI Risk(위험)
데이터 프로세싱 단계에서 명시된 절차 이외에 수행되는 모든 activity 들은 모두 정당성을 가져야만 합니다. 따라서, 데이터 완전성 위험 관리(Risk management) 측면에서 프로세싱과 연관된 데이터 완전성 위험 발생 요소 및 위험 수준을 사전에 평가하고, 적절한 위험 관리를 위한 절차/시스템 구축이 동반되어야 합니다.
* 데이터 프로세싱 단계에서 고려해야한 위험 요소는 아래와 같습니다.
◾ Qualified 된 작업자를 통한 독립된 2nd verification 요구 기준 여부
◾ 작업자를 통해 생성된 최초 데이터의 변경 및 삭제 가능 여부
◾ 최초 생성된 데이터가 overwrite 되거나 삭제 가능 여부 (overwrite 은 이전 데이터 값이 사라지게 되므로, 삭제와 동일한 수준의 action 입니다)
◾ 화면 출력되는(화면에 보이는) 데이터 결과 자체의 수정 가능 여부(Annotation tool; 크로마토그램에 표시가 가능하거나 꼬리말 등을 넣는 기능; 사용)
◾ 재 가공 권한의 제한 가능 여부
◾ 권한이 부여되지 않은 작업자의 프로세싱 파라미터(e.g., Processing method or program) 변경 가능 여부
◾ 파라미터 변경에 대한 이력 기록(log) 생성 여부
◾ Processing 오류나 수동 processing 에 대한 검토 여부
◾ 사용자가 정의한 파라미터의 추적성 확보 가능 여부
◾ 사용자가 데이터 출력 기능/템블릿 에 영향을 줄 수 있는지 여부 (출력 가능한 데이터 및 데이터 스케일 변경 등)
◾ 검증된 계산 기능의 사용 여부
◾ 최종 보고에 제외된 데이터에 대한 정당성과 문서화 여부 (여러번 processing 을 통해 얻어진 결과 데이터 중 1개 데이터만 취사 선택한 것으로 보여질 수 있으므로, 최종 reporting 된 결과의 선택에 대한 정당성을 반드시 명시해야 합니다)
마무리
데이터 프로세싱과 연관된 DI risk 는 대부분 컴퓨터화 시스템을 통해 데이터가 생성/가공/출력되는 단계에서 포함합니다. 데이터의 가공은 보고되는 최종 결과에 직접적인 영향을 주는 단계 이므로, 시스템의 신규 도입 또는 변경 시에 데이터의 가공 단계에서 발생가능한 Risk (전 항목에서 언급한) 에 대한 Gap 을 꼭 사전 평가 해야 합니다.
이때, Risk 가 있는 경우 보완 진행은 1번 순위에서는 기기의 기능(설정, 권한 부여 등) 을 통한 반영이 우선되어야 하며, 기능상 구현이 불가한 경우, 2번 순위로 Verification 또는 Detection 을 높일 수 있는 절차를 수립하는 것이 필요합니다.
[이어서 볼 추천 글]
데이터 완전성을 위한 조직과 데이터 책임감
데이터 완전성(DI) 를 위한 데이터 거버넌스 요소를 모두 이해하지 않아도 좋습니다. 방법적인 사항은 아직 기술하지 않았습니다. 다만, 계속 강조하고 있는 것처럼 최초 기준 수립을 위해 필요
doing-right.tistory.com
'데이터 완전성 (Data Integrity)' 카테고리의 다른 글
| Audit trail review (전자 데이터와 점검 기록 검토) (1) | 2022.04.25 |
|---|---|
| GMP 데이터 검토 (DI 규정에 따른 위험 고려 방법) (0) | 2022.04.19 |
| Data life cycle(데이터 라이프 사이클;데이터 수명 주기) 이해 하기 (0) | 2022.03.31 |
| 데이터 완전성을 위한 조직과 데이터 책임감 (0) | 2022.03.28 |
| 데이터 거버넌스의 시작 (0) | 2022.03.24 |




댓글